---
marp: true
theme: gaia
paginate: true
backgroundColor: #fff
header: "Dateiformate, Schnittstellen, Speichermedien & Distributionswege (223015b)"
footer: "Michael Czechowski – HdM Stuttgart"
title: Dateiformate, Schnittstellen, Speichermedien & Distributionswege
---

# Dateiformate, Schnittstellen, Speichermedien & Distributionswege
**223015b** · Modul "Technik 1" · 1. Semester
Digital- und Medienwirtschaft
Hochschule der Medien Stuttgart
[https://librete.ch/hdm/223015b/](https://librete.ch/hdm/223015b/)
---

---
# Teil 1: Einführung
## Grundlagen, Text & Audio
---
# Das Problem der Datengröße
---
# Ein konkretes Beispiel
**Eine Minute Musik in CD-Qualität:**
44.100 Messungen/Sekunde
× 16 Bit pro Messung
× 2 Kanäle (Stereo)
× 60 Sekunden
= **10,6 MB pro Minute**
---
# Das Problem skaliert
| Inhalt | Unkomprimiert |
|--------|-------------:|
| 1 Song (4 Min) | ~42 MB |
| 1 Album (60 Min) | ~635 MB |
| 10.000 Songs | ~420 GB |
**Kontext 1990er:**
- Festplatte: 100-500 MB
- Modem: 56 kbit/s → 1 Song dauert Stunden
---
# Video eskaliert
**Eine Minute 4K-Video (unkomprimiert):**
3840 × 2160 Pixel
× 3 Byte pro Pixel (RGB)
× 30 Bilder pro Sekunde
× 60 Sekunden
= **~45 GB pro Minute**
Ein 2-Stunden-Film: über **5 Terabyte**
---
# Kompressionsraten in der Praxis
| Medium | Unkomprimiert | Komprimiert | Faktor |
|--------|-------------:|------------:|-------:|
| 1 Song (4 Min) | ~42 MB | ~4 MB (MP3 320) | ~10× |
| 1 Foto (12 MP) | ~36 MB | ~3 MB (JPEG) | ~12× |
| 1 Min 4K-Video | ~45 GB | ~375 MB (H.264) | ~120× |
---
# Zwei Philosophien der Kompression
---
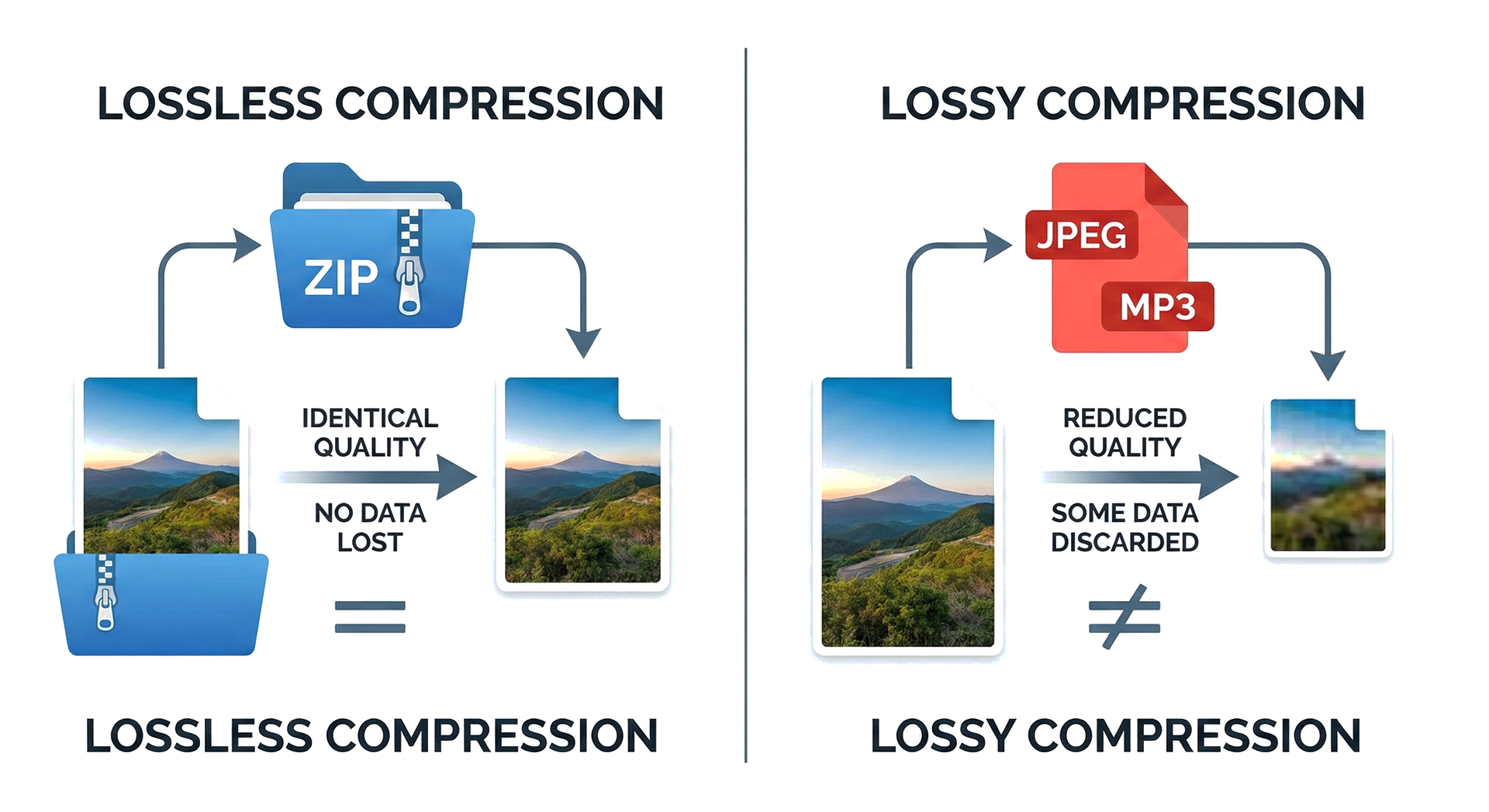
# Verlustfreie Kompression (Lossless)
**Prinzip:** Redundanz entfernen
**Beispiel Lauflängenkodierung:**
```
Original: AAAAABBBCCCCCCCC (16 Zeichen)
Komprimiert: 5A3B8C (6 Zeichen)
```
→ 62% kleiner, 100% wiederherstellbar
**Anwendung:** ZIP, PNG, FLAC, Programmcode
---
# Verlustbehaftete Kompression (Lossy)
**Prinzip:** Irrelevanz entfernen
**Die Frage:** Was nimmt ein Mensch nicht wahr?
- Das Ohr hört nicht alle Frequenzen gleich gut
- Das Auge sieht nicht alle Farbnuancen
- Laute Töne überdecken leise Töne
→ Warum Daten speichern, die niemand wahrnimmt?
---
# Verlustfrei vs. Verlustbehaftet
| | Verlustfrei (Lossless) | Verlustbehaftet (Lossy) |
|---|---|---|
| **Prinzip** | **Redundanz** entfernen | **Irrelevanz** entfernen |
| **Reversibel** | Ja (Original wiederherstellbar) | Nein (Information unwiederbringlich weg) |
| **Reduktion** | 30-50% | 80-99% |
| **Formate** | ZIP, PNG, FLAC, GIF | JPEG, MP3, H.264/H.265 |
**Faustregel:**
- Medien für Endnutzer → Lossy oft akzeptabel
- Quellmaterial, Code, Archive → Lossless nötig
---
---
# Die Grundbausteine
## Bits, Bytes und ihre Darstellung
---
---
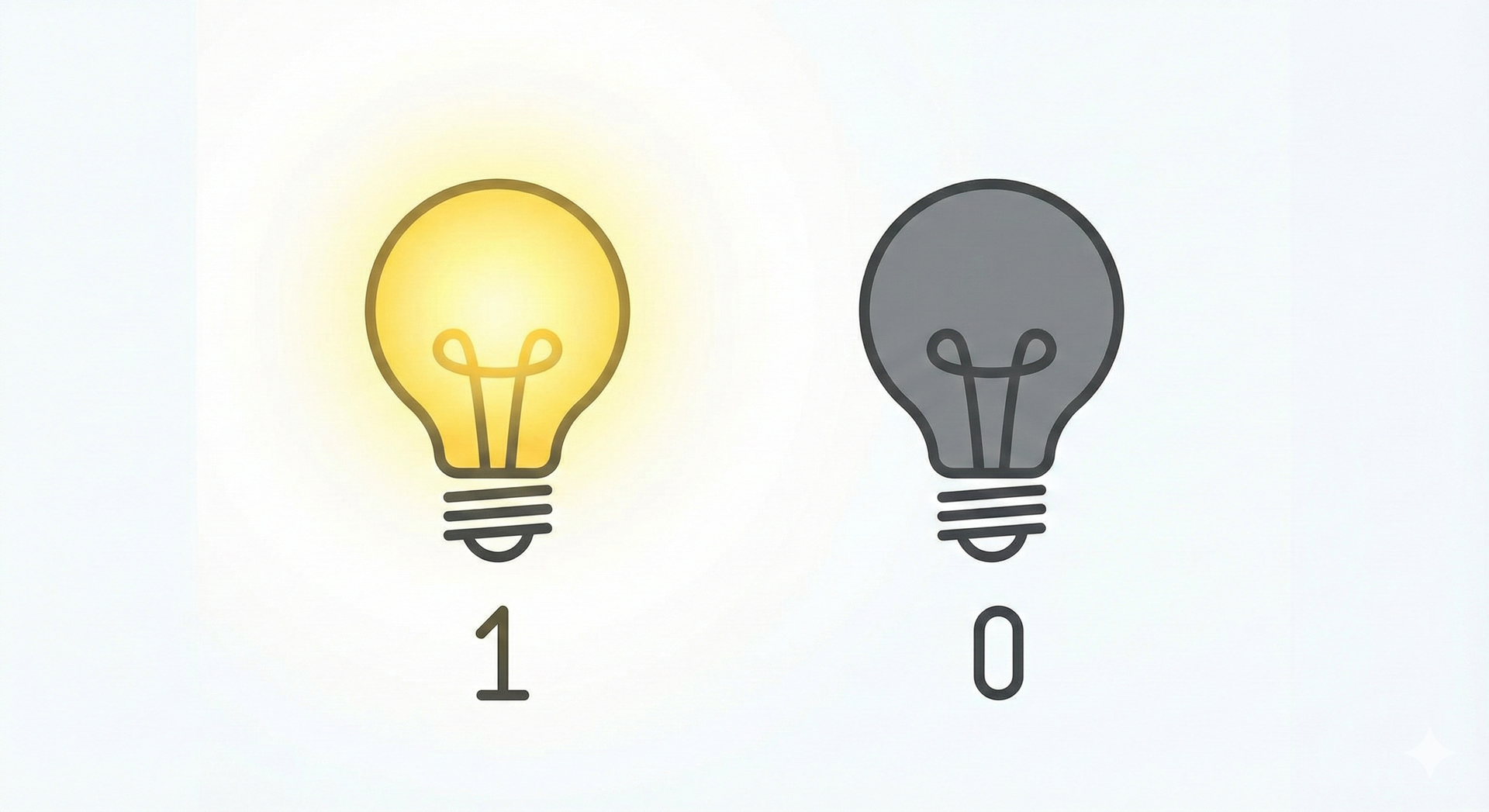
# Das Bit
**Kleinste Informationseinheit**
- **0 oder 1**
- AN oder AUS
- Strom fließt oder nicht
---
# Das Byte
---
# Das Byte
**1 Byte = 8 Bits**
```
0 1 0 0 1 1 0 1
```
---
# Das Byte
**1 Byte = 8 Bits**
```
0 1 0 0 1 1 0 1
```
2⁸ = **256 Möglichkeiten** (0-255)
---
»256 Shades of Gray«

---
# Was kann man mit 256 Zuständen machen?
* **256 Zeichen** (Buchstaben, Zahlen, Symbole)
* **256 Helligkeit bzw. Luminanz** (0 = Schwarz/Dunkel, 255 = Weiß/Hell)
* **256 Lautstärkestufen**
* **Zahlen 0-255** (oder -128 bis +127)
---

---

---

# Farben: RGB-Modell
**1 Pixel = 3 Bytes**
- **Rot:** 0-255
- **Grün:** 0-255
- **Blau:** 0-255
**Beispiele:**
`FF 00 00` = Rot
`00 FF 00` = Grün
`00 00 FF` = Blau
`00 00 00` = Schwarz
`FF FF FF` = Weiß
---
---
# Das Problem: Sprachen
**Die Welt hat mehr als 256 Zeichen!**
- Englisches Alphabet: 52 (A-Z, a-z)
- + Ziffern: 10 (0-9)
- + Sonderzeichen: ~30
**≈ 90 Zeichen → passt in 1 Byte**
**Aber:** ä, ö, ü, ß, é, à, ç, α, β, 中, 日, 😀
→ **1 Byte reicht nicht!**
---
# Unicode: Ein Standard für alle (8 Bit)
**Unicode (1991):** Jedes Schriftsystem der Welt
**>150.000 Zeichen:**
- Latein, Kyrillisch, Arabisch, Chinesisch, Japanisch...
- Mathematische Symbole, Emoji, historische Schriften
**UTF-8:** Variable Länge (1-4 Bytes pro Zeichen)
- **Zeichen 0-127: identisch mit ASCII** (Abwärtskompatibilität!)
- 1.112.064 gültige Zeichen
- Umlaute: 2 Bytes · CJK: 3 Bytes · Emoji: 4 Bytes
---
# Beispiel: Bytes zählen
**Text:** `"Hello·🌸·こんにちは·(Kon-ni-chi-wa)"`
| Zeichen | Bytes |
|---------|-------|
| `Hello·` | 6 × 1 = **6 Bytes** (ASCII) |
| `🌸` | **4 Bytes** (Emoji) |
| `·` | **1 Byte** |
| `こんにちは` | 5 × 3 = **15 Bytes** (Hiragana) |
| `·(Kon-ni-chi-wa)` | **16 Bytes** (ASCII) |
**Gesamt: 42 Bytes** für 29 sichtbare Zeichen
---
# Hexadezimal
## Die Sprache der Datei-Analyse
---
# Hexadezimal: Lesbarkeit
**Binär ist unleserlich:**
`01010000 01001110 01000111`
**Hexadezimal (Base 16):**
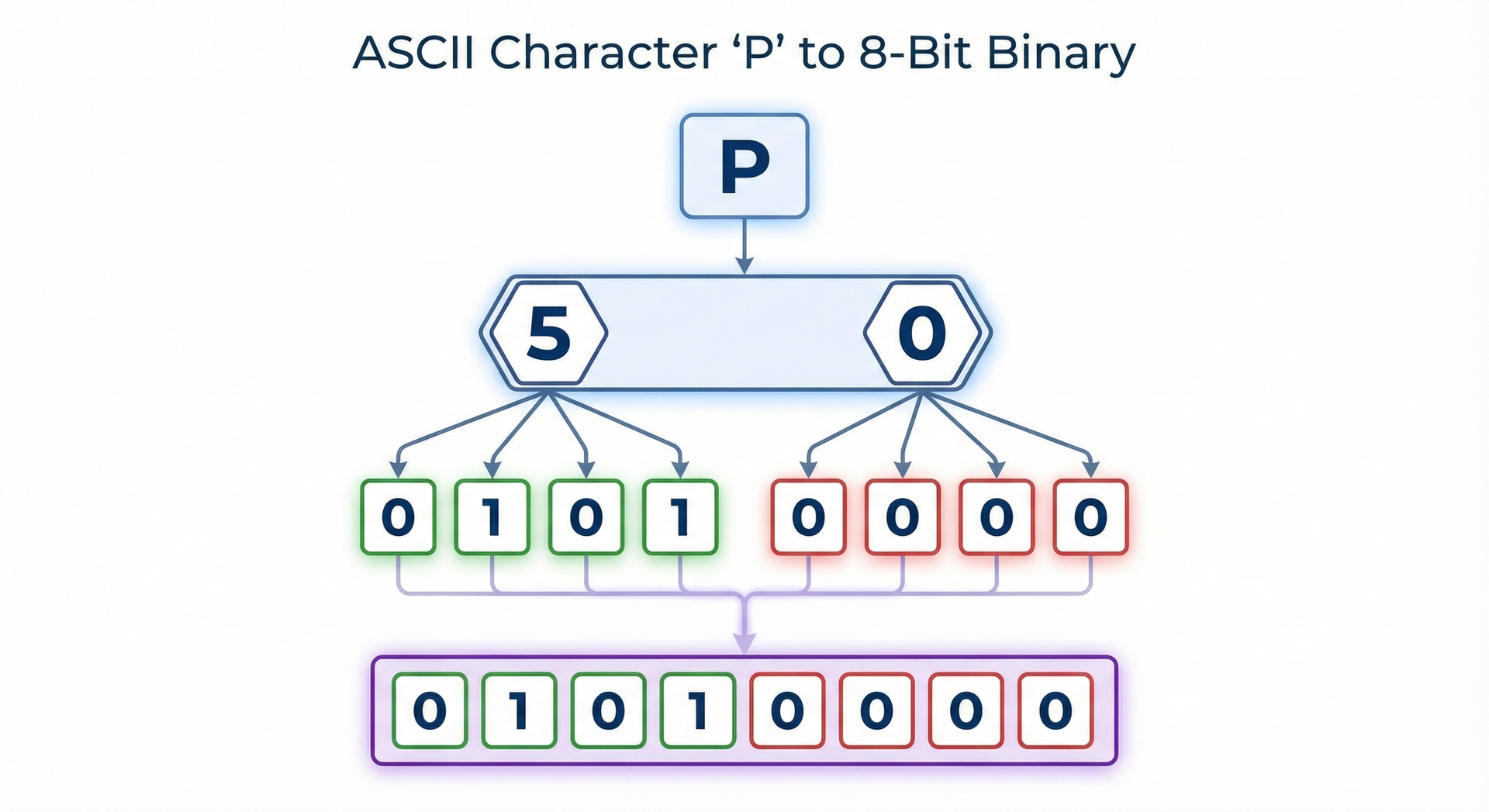
`50 4E 47` (= "PNG" in ASCII)
**Jede Hex-Ziffer = 4 Bits (ein "Nibble")**
0-9, A-F (10=A, 11=B, ..., 15=F)
**ASCII Tabelle (0-127):**
[https://www.asciitable.com](https://www.asciitable.com)
---
# ASCII
## One *Zeichensatz* to rule them all
---

---

# WTF!?
```
89 50 4E 47 0D 0A 1A 0A
00 00 00 0D 49 48 44 52
00 00 01 90 00 00 01 2C
```
---

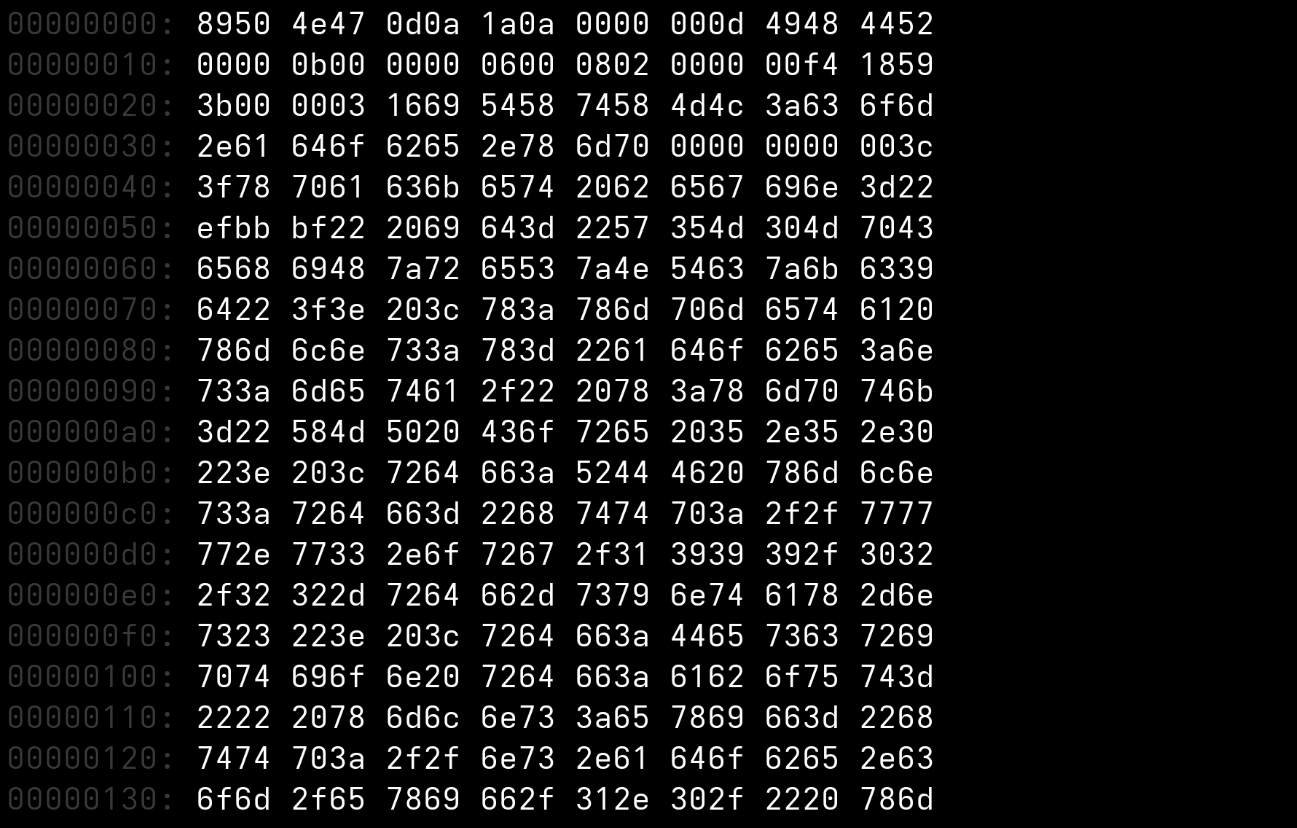
# What the HEX-Code
```
89 50 4E 47 ...
```
| Binär | Hex | Dez | ASCII |
|-------|-----|-----|-------|
| `1000 1001` | `89` | 137 | ✗ (> 127) |
| `0101 0000` | `50` | 80 | **P** |
| `0100 1110` | `4E` | 78 | **N** |
| `0100 0111` | `47` | 71 | **G** |
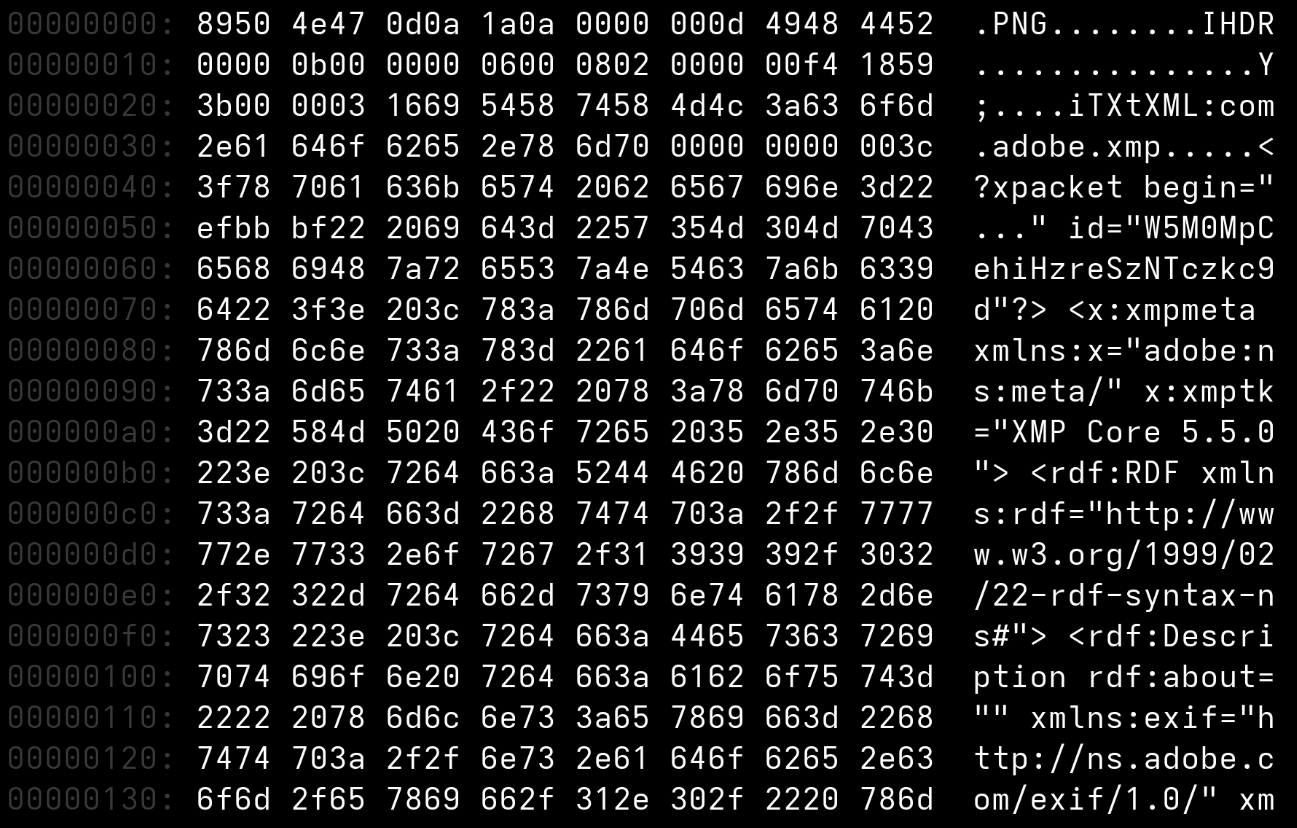
→ **PNG**-Signatur! (Das `89` markiert: "Ich bin binär, kein Text!")
---
---
---
---
# Magic Numbers
**Dateityp-Identifikation durch erste Bytes**
| Format | Magic Number (Hex) | Lesbar? |
|--------|-------------------|---------|
| PNG | `89 50 4E 47` | ✗ P N G |
| JPEG | `FF D8 FF` | ✗ ✗ ✗ |
| PDF | `25 50 44 46` | % P D F ✓ |
| ZIP | `50 4B 03 04` | P K ✗ ✗ |
**Wichtig:** ASCII = nur 0-127! Werte darüber (z.B. `89` = 137) sind **nicht druckbar** (non-printable). *Hex-Editoren zeigen dafür `.` oder `ÿ` als Platzhalter.*
---
# Dateneinheiten
| Einheit | Bytes | Potenz | Beispiel |
|---------|------:|:------:|----------|
| **Byte** | 1 | 10⁰ | Farbwerte eines Pixels |
| **Kilobyte (KB)** | 1.000 | 10³ | Kleiner Programmcode |
| **Megabyte (MB)** | 1 Million | 10⁶ | Textdokument |
| **Gigabyte (GB)** | 1 Milliarde | 10⁹ | Kinofilm in FullHD |
| **Terabyte (TB)** | 1 Billion | 10¹² | ~12h Video in 4K |
| **Petabyte (PB)** | 1 Billiarde | 10¹⁵ | Netflix-Gesamtarchiv |
| **Exabyte (EB)** | 1 Trillion | 10¹⁸ | Alle E-Mails weltweit/Tag |
| **Zettabyte (ZB)** | 1 Trilliarde | 10²¹ | Internet-Traffic 2016 |
---
# Datenwachstum der Menschheit
| Jahr | Datenmenge | Kontext |
|------|------------|---------|
| **100.000 v. Chr.** | 0 | Erste Menschen, nur Sprache |
| **3.000 v. Chr.** | ~wenige KB | Keilschrift, Hieroglyphen |
| **1450** | ~wenige GB | Gutenberg, Buchdruck |
| **1986** | **2,6 EB** | 99% analog (Bücher, Vinyl, VHS) |
| **2007** | **295 EB** | 94% digital |
| **2025** | **181 ZB** | 90% unstrukturiert |
---
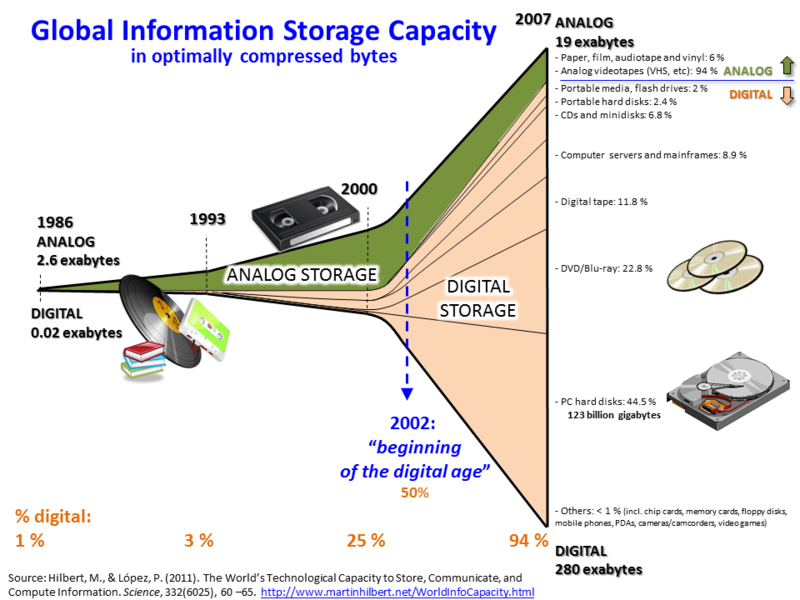
# Der digitale Wendepunkt
| Jahr | Analog | Digital | Digital-Anteil |
|------|--------|---------|----------------|
| **1986** | 2,6 EB | 0,02 EB | **1%** |
| **2002** | — | — | **50%** (Wendepunkt) |
| **2007** | 18 EB | 277 EB | **94%** |
**Perspektive:**
- 1986: "Petabyte" war ein theoretisches Konzept
- 2025: ~181 Zettabyte jährlich produziert
**Magnetband lebt:** LTO-Tapes bleiben günstigstes Archivmedium
(AWS Glacier, Film-Archive, Rechenzentren)
---
---
# 181 Zettabyte – Was bedeutet das?
**2025:** Welt erzeugt **181 ZB** pro Jahr
- **2,5 Quintillionen Bytes** täglich
- **29 Terabyte** pro Sekunde
- **90%** davon: unstrukturiert (Videos, Bilder, Audio)
- **70%** davon: von NutzerInnen generiert
**Zum Vergleich:**
- 1 ZB = 250 Milliarden DVDs
- 181 ZB = Jeder Mensch erzeugt ~23 TB/Jahr
---
# AI-generierte Inhalte 2025
**Wie viel Content ist heute synthetisch?**
| Bereich | AI-Anteil |
|---------|-----------|
| **Neue Webseiten** | ~74% enthalten AI-Content |
| **Web-Text gesamt** | ~30-40% AI-generiert |
| **Neue Artikel** | ~52% von AI geschrieben |
| **Social-Media-Bilder** | ~71% AI-generiert |
**Prognose 2026:** 90% des Online-Contents synthetisch
---
# Teil 2: Die MP3-Revolution
## Psychoakustik & Audio-Kompression
---

---
# Analoge Medien
### Distribution: physisch (Kauf, Verleih, Kopie)
* **Text**
- Bücher, Zeitungen, Zeitschriften, Lochkarten
* **Bild**
- Fotografie (Negativ, Dia, Polaroid), Mikrofilm
* **Audio:**
- Schallplatte (Vinyl, Schellack), Tonband, Musikkassette
* **Video:**
- Film (35mm, Super 8), VHS, Betamax
---
# Analoge Medien: Vor- und Nachteile
| Vorteile | Nachteile |
|----------|-----------|
| Kein Abspielgerät nötig (Buch, Foto) | Qualitätsverlust bei jeder Kopie |
| Haptisches Erlebnis | Physischer Verschleiß |
| Unabhängig von Strom/Internet | Begrenzte Haltbarkeit |
| Keine Formatkonvertierung | Platzbedarf bei Lagerung |
| Eindeutiges Original | Aufwendige Durchsuchbarkeit |
---
# Von Analog zu Digital: Die Kopier-Revolution
**Das Problem analoger Kopien:**
Kassette → Kassette → Kassette = immer schlechter
**Was Digital anders macht:**
- **Identische Kopien** – kein Qualitätsverlust, nie
- **Einfache Massenproduktion** – Copy & Paste
- **Perfekte Archivierung** – Bits verändern sich nicht
**Daher: "Raubkopien"**
Der Begriff entstand, weil digitale Kopien *tatsächlich identisch* mit dem Original waren – nicht wie bei Kassetten eine schlechtere Version.
Quelle: [c64-wiki.de/wiki/Raubkopie](https://www.c64-wiki.de/wiki/Raubkopie)
---
# Digitale Medien
### Distribution: Datenträger (CD, USB), Download, Streaming, P2P
* **Text**
- E-Book (PDF, EPUB), Dokumente (TXT, DOCX)
* **Bild**
- Digitalfoto (JPEG, PNG, RAW, WebP, GIF)
* **Audio**
- Audiodatei (MP3, FLAC, WAV, AAC, OGG)
* **Video**
- Videodatei (MP4, MKV, AVI, WebM)
---
# Digitale Speichermedien
* **Optische Speicher**
- CD, DVD, Blu-ray
* **Magnetische Speicher**
- Festplatte (HDD), Magnetband (LTO)
* **Flash-Speicher**
- SSD, USB-Stick, SD-Karte
* **Cloud-Speicher**
- Dropbox, Google Drive, iCloud, AWS S3
---
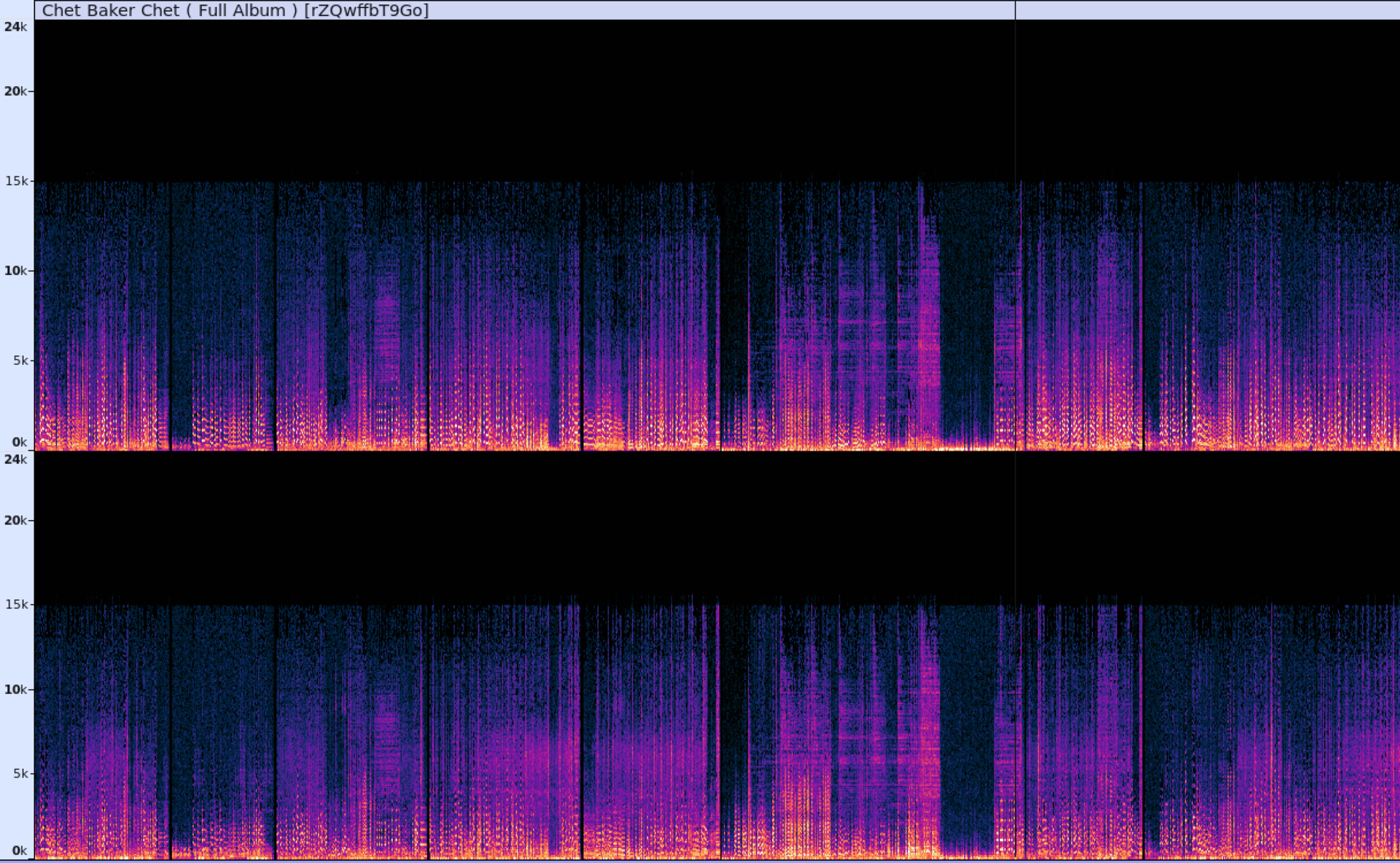
# Das Speicherproblem der Digitalisierung
**Ziel: Analoge Schallwelle möglichst originalgetreu rekonstruieren**
*CD-Qualität (1982): 44.100 Hz × 16 Bit × 2 Kanäle = 10,584 MB/Minute*
| Inhalt | Größe | Problem (1990er) |
|--------|-------|------------------|
| 1 Song (4 Min) | ~42 MB | Ausreichend Speicher |
| 1 Album (60 Min) | ~635 MB | Gesamte Festplatte |
---
---
# Die Abtastrate (Sample Rate)
**Analog → Digital ≙ Kontinuierlich → Diskret**
```
Analog (Vinyl): Digital (CD):
~~~~~~~~~~~~~~~ • • • • • • • •
Kontinuierliche 44.100 Messpunkte
Wellenform pro Sekunde
```
**Nyquist-Theorem:**
> Um eine Frequenz zu rekonstruieren, braucht man mindestens **2× so viele Samples**.
44.100 Hz ÷ 2 = **22.050 Hz** max. darstellbare Frequenz
(Mensch hört: ~20 Hz bis ~20.000 Hz → passt!)
---
# Die Bittiefe (Bit Depth)
**Wie genau messen wir jeden Punkt?**
| Bittiefe | Stufen | Dynamikumfang |
|----------|--------|---------------|
| 8 Bit | 256 | ~48 dB |
| 16 Bit (CD) | 65.536 | ~96 dB |
| 24 Bit (Studio) | 16.777.216 | ~144 dB |
**16 Bit = 2¹⁶ = 65.536 Lautstärkestufen**
(von absoluter Stille bis maximaler Lautstärke)
---
# Abtastrate (Sample Rate) × Bittiefe (Bit Depth)
**Zwei Dimensionen der Digitalisierung:**
| Dimension | Was bedeutet es? | CD-Qualität |
|-----------|------------------|-------------|
| **Abtastrate** (Sample Rate) | Messungen pro Sekunde (horizontal) | 44.100 Hz |
| **Bittiefe** (Bit Depth) | Genauigkeit pro Messung (vertikal) | 16 Bit |
**44.100 Hz × 16 Bit** × 2 Kanäle = 10,584 MB/Minute
---
# Kompression
## Weniger Daten, gleiche(?) Information
---
# Wo liegt der Hebel für Kompression?
**CD-Qualität:** 44.100 Hz × 16 Bit × 2 Kanäle = **10,6 MB/Min**
**MP3 (128 kbps):** = **~1 MB/Min** (Faktor 10!)
**Container-Parameter (das Raster):**
| Parameter | Reduzieren → | Konsequenz |
|-----------|--------------|------------|
| Abtastrate | Weniger Messpunkte/Sek | Max. Frequenz sinkt |
| Bittiefe | Weniger Lautstärkestufen | Mehr Rauschen |
| Kanäle | Mono statt Stereo | Kein Raumklang |
---
# Psychoakustik: Der MP3-Trick
**Inhalt (was durchs Raster geht):**
| Methode | Reduzieren → | Konsequenz |
|---------|--------------|------------|
| Psychoakustik | Unhörbare Frequenzen | Kaum wahrnehmbar |
→ **MP3 nutzt hauptsächlich Psychoakustik**
→ Container bleibt ähnlich, Inhalt wird "ausgedünnt"
---
# Die Geburt der MP3
**1982:** Universität Erlangen-Nürnberg
Karlheinz Brandenburg, Diplom-Ingenieur
**1987:** Fraunhofer IIS entwickelt MPEG-1 Audio Layer III
**1988:** Patentanmeldung
**1992:** Erste Software-Implementierung
**1995:** .mp3 Dateiendung offiziell
---

# Karlheinz Brandenburg
**"Vater der MP3"**
- Diplom-Ingenieur, Universität Erlangen-Nürnberg
- Fraunhofer IIS (Institut für Integrierte Schaltungen)
- Forschung ab 1982, Patent 1988
---

# Suzanne Vega
**"Tom's Diner" (1987)**
- Der erste Song, der als MP3 kodiert wurde
- A cappella (keine Instrumente)
- Klare, hohe Frequenzen
- Perfekter Stresstest für Kompression
- Brandenburg hörte "Tom's Diner" über 10.000 Mal
---
# Wie funktioniert MP3?
Ein Zusammenspiel aus vielen Faktoren:
* **1. Frequenz-Analyse (FFT)**
Audio → Frequenzspektrum
* **2. Psychoakustisches Modell**
Welche Töne hört Mensch nicht?
* **3. Quantisierung**
Unwichtige Frequenzen reduzieren
* **4. Huffman-Coding**
Lossless-Kompression der Restdaten
---
# Bitrate: Der Qualitäts-Knopf
| Bitrate | Qualität | Kompression |
|---------|----------|-------------|
| **128 kbps** | Hörbar schlechter | ~11x |
| **192 kbps** | Akzeptabel | ~7x |
| **256 kbps** | Gut | ~5,5x |
| **320 kbps** | "CD-Qualität" | ~4,4x |
**Original CD:** 1.411 kbps (unkomprimiert)
---
# Der Patentkrieg
**1990er:** Fraunhofer + Thomson halten MP3-Patente
**Lizenzgebühren:**
- $0,75 pro Decoder
- $2,50 pro Encoder
**Problem:** Napster (1999) → unkontrollierte Verbreitung
**2017:** Patente laufen aus → MP3 ist frei
---
# Napster (1999)
**P2P-Filesharing für MP3s**
- Shawn Fanning, 19 Jahre alt
- 80 Millionen User in 2 Jahren
- Musikindustrie verklagt (2001)
- Pandora's Box: Nicht mehr aufzuhalten
---
# Napster & Musikindustrie
**1999:** Napster startet
**2001:** 80 Millionen User
**Musikindustrie:**
- CDs kosten $15-20
- MP3s gratis (illegal, aber yolo)
- Einzelne Songs statt Alben
**2001:** Napster wird verklagt und schließt
**Aber:** Pandora's Box offen
→ LimeWire, Kazaa, BitTorrent, später Spotify
---
# Kulturelle Revolution
**MP3 veränderte:**
✓ Musik wurde portabel (Walkman → iPod)
✓ Alben wurden irrelevant (Playlists)
✓ Musikkonsum explodierte (kostenlos/billig)
✓ KünstlerInnen verloren Kontrolle
**Aber auch:**
❌ KünstlerInnen verdienen weniger pro Stream
❌ Audio-Qualität sank (Loudness War)
❌ Physische Medien starben
---
# Fragen & Diskussion
**Kontakt:** mail@librete.ch
**Folien:** Online verfügbar unter https://librete.ch/hdm/223015b
---
# Lizenz & Attribution
Diese Präsentation ist lizenziert unter **Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)**
- Erlaubt Teilen & Anpassen mit Namensnennung
- Adaptionen müssen unter gleicher Lizenz geteilt werden
Vollständige Lizenz: https://creativecommons.org/licenses/by-sa/4.0/
---
# Selbstlernen: Audio-Spektrogram
**Aufgabe (30 Min):**
- Live Spektrogram untersuchen https://borismus.github.io/spectrogram/
- Mit Effekten experimentieren https://audiomass.co/
- Spektrogramme vergleichen Audacity (kostenloser Download nötig) [https://manual.audacityteam.org/man/spectrogram_view.html](https://manual.audacityteam.org/man/spectrogram_view.html)
---

# Selbstlernen: HEX Files
1. Drei Dateien ohne Dateiendung:
`hex1` `hex2` `hex3`
3. Lies erste 16 Bytes aus und identifiziere Dateiformat (Magic Number)
5. *Optional: Datei umbenennen und korrekte Dateiendung anhängen (bspw. `.jpg`)*
**Tools:**
- Hex-Editor: [hexed.it](https://hexed.it)
- Magic Numbers: [en.wikipedia.org/wiki/List_of_file_signatures](https://en.wikipedia.org/wiki/List_of_file_signatures)